
(原标题:刚刚!DeepSeek,传出重磅消息!)
DeepSeek,又刷屏了!
周末,DeepSeek官宣永久降价的消息,引发大量关注。日前,DeepSeek在其官网宣布,DeepSeek-V4-Pro API永久降价至原价的25%。
另据彭博社消息,DeepSeek正在推进700亿元人民币(约合100亿美元)的融资,这比之前传出的500亿元规模更大,有望创下中国AI企业史上最大单笔融资纪录。该公司将继续开发开源 AI模型 ,同时追求实现通用 人工智能 (AGI)这一更宏大的目标。
DeepSeek官宣永久降价
券商 中国记者注意到,DeepSeek日前在其官网宣布,DeepSeek-V4-Pro模型API价格将于2026年5月31日结束2.5折优惠活动后,正式调整为原定价的1/4。
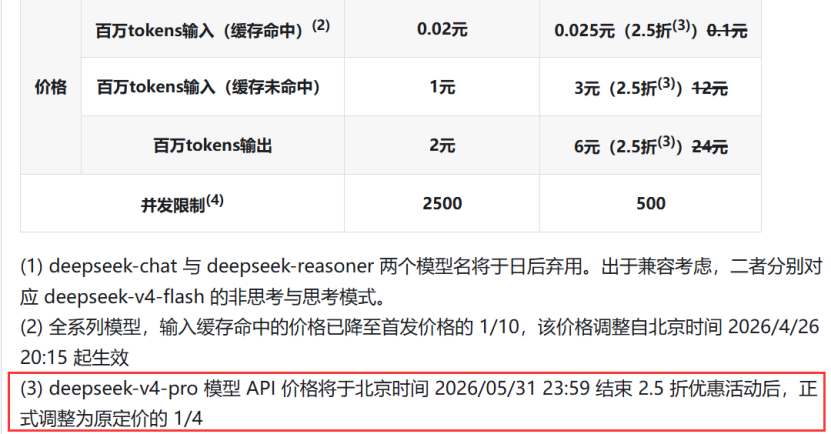
此前4月26日,DeepSeek官方发布API价格调整公告,全系API输入(缓存命中)价格降至首发价的十分之一,V4‑Pro更叠加限时1/4(相当于2.5折)的优惠。
上述API2.5折优惠活动,原定6月起恢复原价,但最新公告确认,DeepSeek-V4-Pro API将永久降为原价的1/4,即:每百万Tokens输入(缓存命中)0.025元,输入(缓存未命中)3元,输出6元,创全球大模型价格新低。
今年4月24日,DeepSeek“无预警”发布了新一代旗舰大模型DeepSeek-V4并开源。新模型在推理性能等方面比肩全球一流闭源模型,且延续其性价比优势,以极低的推理成本、标配的高性能长文本能力,引发广泛关注。
据悉,相比前代模型,DeepSeek-V4-Pro的Agent能力显著增强。在Agentic Coding评测中,V4-Pro已达到当前开源模型最佳水平,并在其他Agent相关评测中同样表现优异。目前DeepSeek-V4已成为该公司内部员工使用的Agentic Coding模型,据评测反馈使用体验优于Sonnet 4.5,交付质量接近Opus 4.6非思考模式,但仍与Opus 4.6思考模式存在一定差距。
DeepSeek-V4-Pro在世界知识测评中,大幅领先其他开源模型,仅稍逊于顶尖闭源模型Gemini-Pro-3.1。
在数学、STEM、竞赛型代码的测评中,DeepSeek-V4-Pro超越当前所有已公开评测的开源模型,取得了比肩世界顶级闭源模型的优异成绩。
有券商指出,DeepSeek V4模型实现超长上下文、推理及Agent能力全面升级,叠加CSA/HCA混合注意力架构带来显著成本与性能优势,同时 华为昇腾 、 寒武纪 、 摩尔线程 、 沐曦股份 、 海光信息 等国产算力厂商完成快速适配,芯模协同生态持续完善,有望带动AI大模型及国产算力产业链需求加速释放。建议关注国产 AI芯片 产业链的投资机会。
正在推进700亿元融资
据彭博社消息,知情人士透露,DeepSeek高管已向正在进行中的700亿元人民币(约合100亿美元)融资轮次的潜在投资者表示,这家初创公司将优先进行突破性的人工智能研究,而非短期商业化。
其中一位知情人士称,DeepSeek创始人梁文锋在至少一次与投资者的会议上承诺,将继续开发开源AI模型,同时追求实现通用人工智能(AGI)这一更宏大的目标。这位对冲基金经理兼AI先驱明确表示,主要目标是推动技术发展边界而非变现。
报道称,这家在2025年以成本远低于同行的AI模型颠覆硅谷的中国公司,已吸引大量投资者的浓厚兴趣。据知情人士透露,该公司正处于融资交易讨论的最后阶段,此轮投资前对DeepSeek的估值可能约为450亿美元。
知情人士表示,DeepSeek的可能投资者包括国家人工智能产业投资基金。据称,腾讯、IDG资本和砺思资本也接近确定参与投资。其中一位知情人士还表示, 网易 也寻求参与投资,京东也在洽谈加入本轮融资。
讨论仍在进行中,从投资金额到最终参与者的细节仍可能发生变化。总体而言,DeepSeek专注于AI研发而非盈利的定位,与其一贯的AI行业做法相符。中国开源模型因其广泛的可得性而在全球用户激增,这种做法由DeepSeek率先推广,并被 阿里巴巴 及其通义千问平台成功采用。
与此同时,全球AI公司正面临越来越大的压力——在计算基础设施投入数千亿美元后,需要开始实现盈利。在全球同行(从OpenAI到Anthropic)纷纷探索公开上市和多种创收新途径之际,梁文锋“研究优先”的理念显得格外突出。
若最终敲定,DeepSeek此次融资可能创下中国科技初创公司首轮融资的纪录。其中一位知情人士表示,国家人工智能产业投资基金正在洽谈投资约100亿元人民币。
知情人士称,梁文锋可能在此轮融资中个人出资约200亿元人民币。在OpenClaw出现后,这家初创公司正顺势扩展至智能体AI领域,抓住对无需人工干预即可执行任务的 软件 的热情浪潮。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}